
Elephant Flows
In LAG/ECMP load-balancing, all packets of a flow are sent on a single link or path. If a particular flow exceeds the chosen link or path bandwidth, it is called an elephant flow. With flows not being distributed equally across links/paths, having elephant flows could introduce congestion in the network.
Elephant flows could be due to the number or nature of fields chosen to define a flow (coarse granularity) or due to actual network traffic for a particular flow being quite high.
Possible solutions for this problem are -
Adding additional packet fields: This can break down a single elephant flow into multiple flows thereby increasing the entropy so that they get distributed across multiple links/paths. Note that this will help only if the additional fields being added to the hash have varying values instead of the same single value.
Vendor solutions: However additional fields may not always help, so some vendors provide solutions that monitor current link usage and reassign flows to different links if a particular link exceeds a certain threshold.
Polarization
When traffic passes through more than one load-balancing router all of which use the same hashing algorithm (e.g. same vendor), the first load-balancing router will distribute the traffic. But when this portion of traffic reaches a subsequent router on one of these paths, it ends up selecting a single outgoing path instead of distributing it amongst all its available paths.
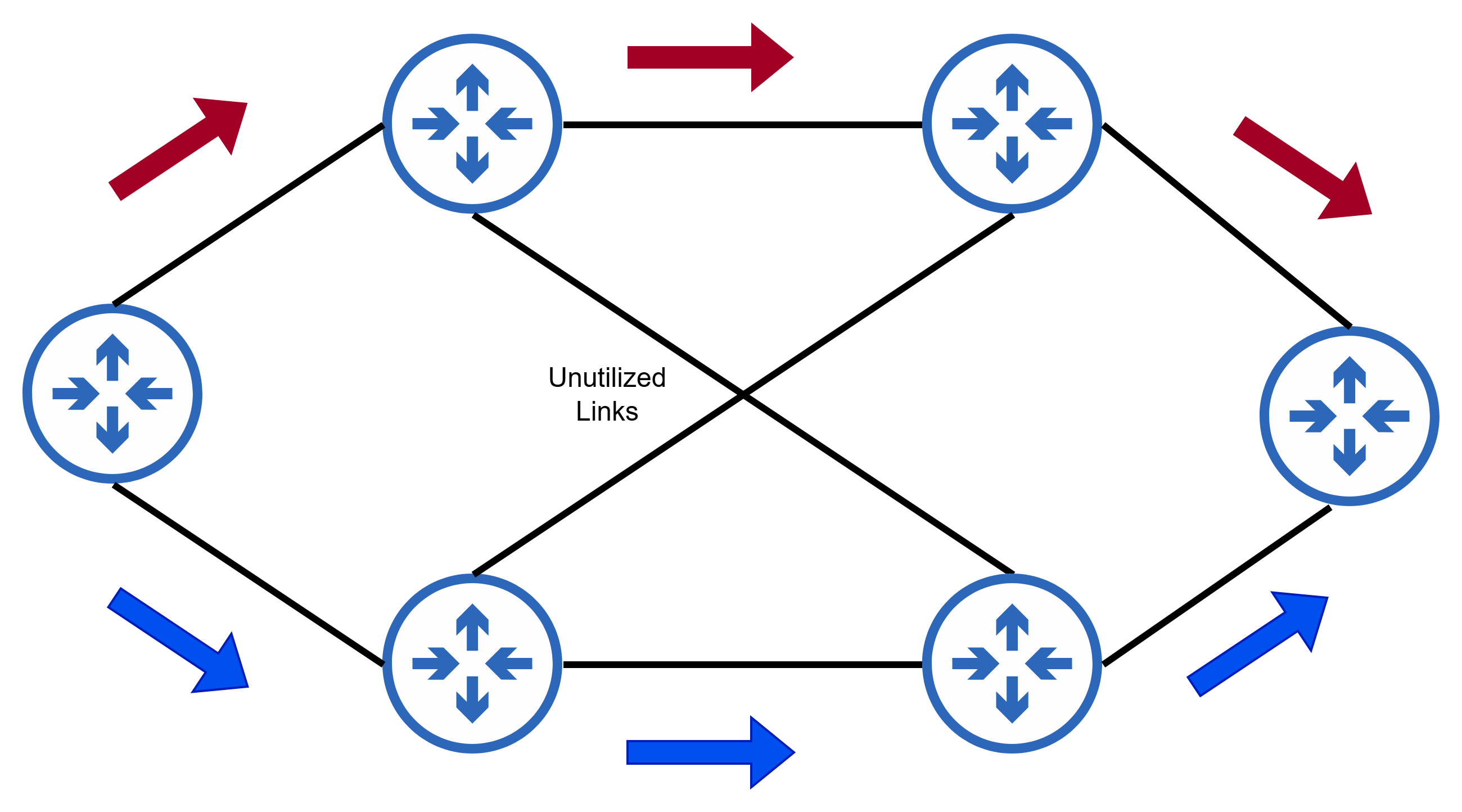
In the above diagram, the first router on the path distributes traffic into two paths - red traffic and blue traffic. But when the red traffic reaches the subsequent router, it fails to distribute the traffic further and instead sends all of it only on one link leaving the other link unutilized. Similarly for the blue traffic.
This happens because each router uses the same hashing algorithm and the same packet fields (hash input) on the same packet content resulting in the same link number (0 for red, 1 for blue) being computed.
The solution to the polarization problem is to introduce some randomness in the hash calculation at each router e.g. by rotating the hash by a different delta at each node in the path. The exact mechanisms of rotating the hash are vendor-dependent. One simple example could be - if the hash algorithm results in link n as the output link, and the rotate delta configured on the router is m, the final link chosen to egress the packet could be (n+m) % n. For all routers on the path using the same hash algorithm, we configure a different value of m.
Unnecessary flow remapping
When a link or path fails for any reason, the traffic on that link or path needs to be redistributed to other working links/paths. But depending on the hashing algorithm used, any change in the number of paths may affect not only the flows that were using the affected path but also affect flows on unaffected paths.
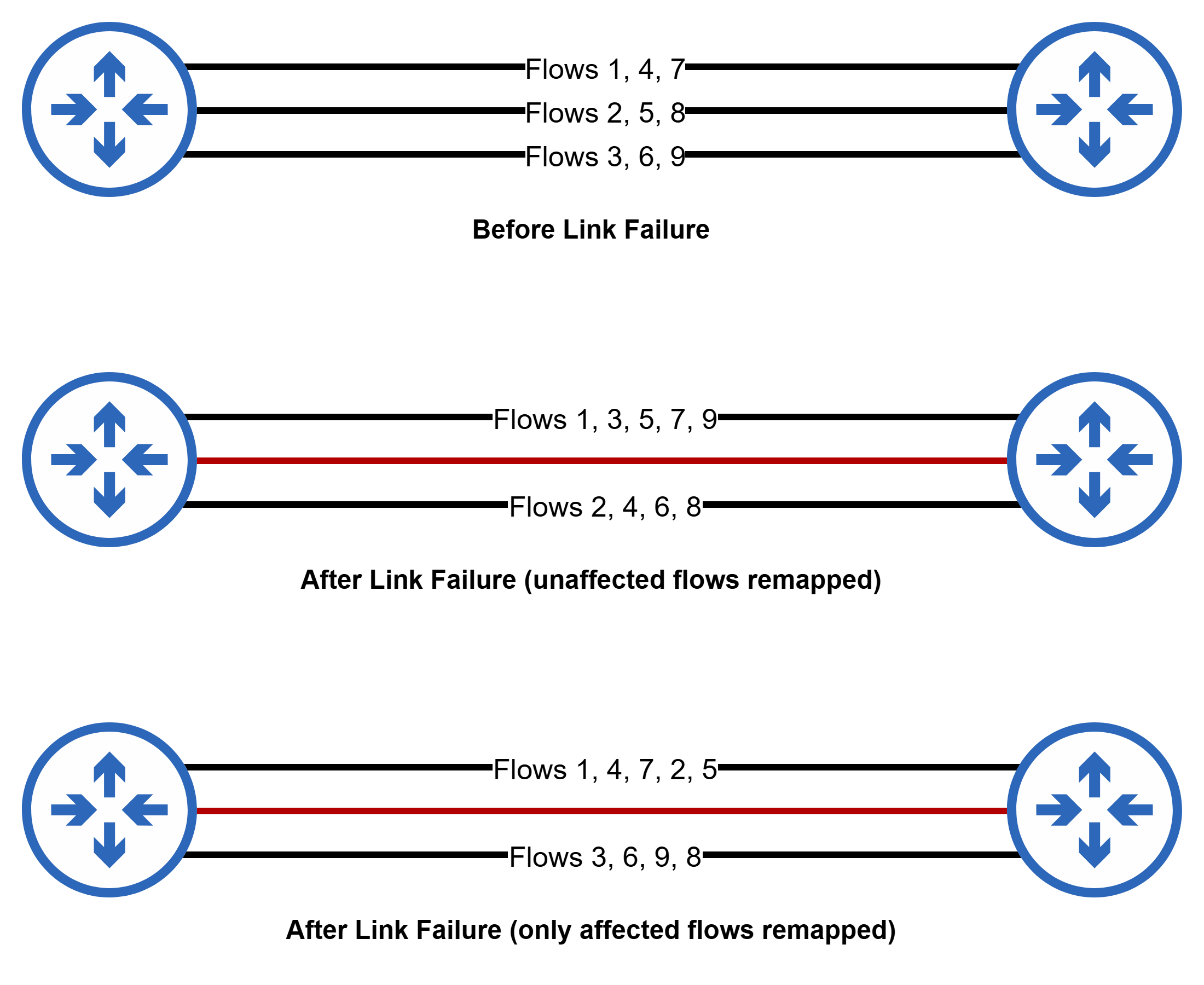
In the above diagram, when link 2 fails, flows 3 and 9 are unaffected by the failure but get remapped from link 3 to link 1 and flow 4 from link 1 to link 3 which is unnecessary. Not just unnecessary, but maybe even undesirable for some use cases e.g. where the other end may be doing flow-aware processing.
The problem will also been when removing or adding links.
To avoid this, vendors implement load balancing algorithms to minimize flow remapping in cases of failures - this feature is often called consistent hashing or resilient hashing.
Symmetric load-balancing
For some use cases which have stateful middle boxes such as NAT or stateful firewalls, you may want the flow and its counterpart reverse flow go via the same box. However, since each router takes its load balancing decision independently, this may not happen by default.
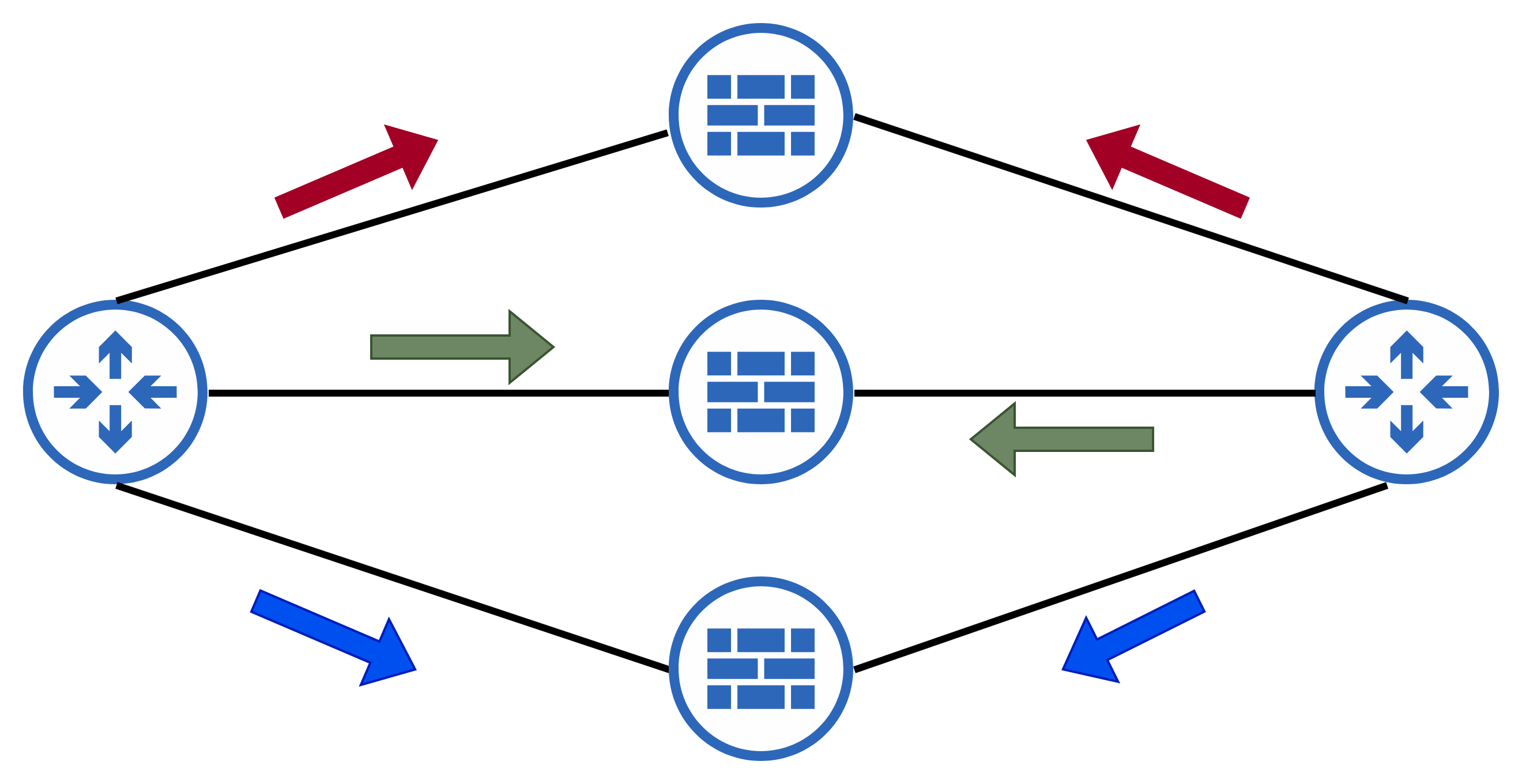
To achieve this, you will want to use only the source IP [+ source L4 Port] as the hash fields in one direction while in the reverse direction, you will use the destination IP [+ destination L4 port]. You can either explicitly specify the hash fields on each router or some vendors may offer a feature where you can configure the source and destination IP and L4 port to be automatically swapped when computing the hash for a portion of the traffic.
Verifying load-balancing with Ostinato
To verify load-balancing you need to generate multiple flows. Ostinato allows you to vary IP addresses easily. A single Ostinato stream can generate packets with different IP addresses.

To vary the L4 source or destination port - as a matter of fact, to vary any packet field, you can configure variable fields in the Ostinato stream

Is there some load-balancing related verification that you would like Ostinato to make easier for you? Let us know!